Google Compute Engine endeavors to provide nimble, reliable, and inexpensive compute power for your software services. Beyond CPU and memory, most applications require high performing and reliable block storage. For that the Google Cloud Platform offers Compute Engine Persistent Disks.
In building the hardware and software infrastructure for Persistent Disks, Google engineers put top priority on:
With the scale that Google builds datacenters, it is able to make these critical features of Persistent Disk available to you at a consistent, reliable, and low price. This paper provides an overview of the features and performance details of Persistent Disks to allow you to get the most out of them.
Compute Engine Persistent Disk provides network-attached block storage, much like a high speed and highly reliable Storage Area Network (SAN), to Compute Engine instances.
The core features of Google Persistent Disk are:
In addition, by providing storage as a service, Persistent Disks offer manageability features that make your storage more nimble.
Persistent Disks can be
All of these features are available from two storage options that allow you to scale up your applications and pay only for the performance you need. Compute Engine offers:
Persistent Disks have built-in redundancy to protect your data against equipment failure and to remain available through datacenter maintenance events. Your instances, free of local storage, can be moved by Google Live Migration to newer hardware without your intervention. This allows Google datacenters to be maintained at the highest level; software, hardware, and facilities can be continually updated to ensure excellent performance and reliability for your cloud-based services.
Persistent Disk stripes data across many physical volumes within a zone to improve performance consistency. As a result, volumes of the same size in the same zone generally perform at the same level at a given time. Volume performance can vary over time as the aggregate IO load of the zone rises and falls, but by striping across many physical volumes, that variability is greatly reduced.
Persistent Disk data is always encrypted when it is outside of your virtual machine instance. When the instance sends a write to disk, the data is transparently encrypted before it goes over the network. When your instance reads data from disk, the data is decrypted when it has returned from the network. At rest and in flight, your Persistent Disk data is encrypted.
Checksums are calculated for all Persistent Disk IOs so we can ensure that what you read is what you wrote. Persistent Disk guarantees that data is stored with built-in redundancy. If any bytes on disk are lost or corrupted, we can usually determine what the bytes should be. If the loss or corruption is so severe that we can't recover, the read will fail; Persistent Disk will never return corrupted data.
Persistent Disks live independently of the Compute Engine instance(s) they are attached to. This allows for Persistent Disks to be managed in ways not typically available to locally attached disks offered with compute services.
Need to take down a Compute Engine instance to resize it or to replace or upgrade the running software? You won't lose the associated data; you won't need to rebuild the volume. Take the instance down and then create a new one with the volume attached.
For example when looking at the lifecycle of a database such as MySQL, MongoDB, or Cassandra, this ability to perform quick upgrades of software or virtual hardware can significantly lower the maintenance burden. Not needing to rebuild a local ephemeral disk means:
Whether on-premises or in the cloud, you need an effective backup strategy. Google Compute Engine Persistent Disk volumes can be backed up on a regular basis using Snapshots.
Thanks to Persistent Disk design snapshots can be taken quickly, and repeated snapshots of the same Persistent Disk are incremental. This means that only changes since the previous snapshot are stored, reducing your snapshot storage charges.
Snapshots are automatically replicated across multiple zones, whereas Persistent Disk redundancy is within a zone. So if you take regular snapshots, and an entire zone were completely lost in a disaster, you could quickly recover by creating new Persistent Disks in another zone. Also if an end user deleted critical data, you could create a new Persistent Disk from a previous snapshot to recover.
When you create a new Persistent Disk volume from a snapshot, you can specify a volume size larger than that of the original. This allows you to be conservative with volume sizing as you build out your deployment. You can start with a modestly sized volume during development and initial testing, then create a new volume from snapshot. You should find this to be much faster than creating a new volume and manually copying the data from the original volume.
When you create a new Persistent disk volume from a snapshot, you can specify the Persistent Disk type for the new volume. This allows you to start with a Standard Persistent Disk volume during development and initial testing, and then create a new SSD Persistent Disk volume from a snapshot of the original to take advantage of the increased performance.
Persistent Disks can be attached to multiple nodes in read-only mode (when not attached to any instance in read-write mode). You can distribute static content across multiple Compute Engine instances without incurring the cost of replicating the storage.
There are complexities and costs typically associated with block storage that Compute Engine Persistent Disks do away with.
Persistent Disks give consistent performance. There is no need to spin up a bunch of extra disks, test them for performance, and select only the best. There are no outliers to discard.
You have no need to aggregate multiple disks in a RAID array to get improved performance and reliability. Google already stripes your data across multiple disks, so you are getting the performance of parallel I/O and the reliability of replicated blocks.
When you add a volume, that volume is available to run at full speed. There is no need to pre-warm the volume; doing so needlessly consumes resources.
Determining the right Persistent Disk volume type and size requires consideration of both your storage size and performance requirements.
Performance requirements for a given application are typically separated into two distinct IO patterns: "small random IOs" and "large IOs". For small reads and writes, the limiting factor is random input/output operations per second (IOPS). For large reads and writes, the limiting factor is throughput (MB/s).
This section will give you an overview, some rules of thumb, and some lookup charts for quick reference. The subsequent section will walk through example computations to help select the right storage for production environments.
Performance for Persistent Disk increases with volume size up to the per-VM maximums. While Performance increases with volume size for both Standard and SSD PD, the performance increases much more quickly for SSD PD.
Standard Persistent Disk sustained performance caps increase with the size of the volume until reaching the maximum performance available. These performance caps are for sustained activity to disk, not peak IO rates. We recognize that for many applications, IO is bursty and so for small volumes (less than 1 TB) Google has implemented a bursting capability that enables short bursts of IO above the documented caps. Once that burst is exhausted, the IO rates drop to the documented caps. This bursting capability can enable you to select your volumes based on their sustained rate rather than the peak rate. Depending on the burstiness of the workload, this can result in substantial cost savings.
The following table illustrates the performance limits for a 100 GB Standard Persistent Disk volume for each of the IO patterns.
| Maximum Sustained IOPS / 100 GB (scales linearly up to 10 TB) | Maximum Sustained throughput / 100 GB | Maximum Sustained throughput / VM | |
|---|---|---|---|
| Read | 30 IOPS | 12 MB/s | 180 MB/s |
| Write | 150 IOPS | 9 MB/s | 120 MB/s |
Standard Persistent Disk performance caps increase linearly with the size of the disk, from the smallest (1 GB) disk to the largest (10 TB). Thus if you require only 60 small random read IOPS per volume, you only need 200 GB, but if you require 600 small random reads IOPS, then you would purchase at least a 2 TB volume.
Throughput maximums also scale with volume size up to a VM limit.
Standard Persistent Disk volumes can be up to 10 TB. This corresponds to a maximum of up to 3000 random read IOPS or 15000 random write IOPS.
The VM limit for Standard Persistent Disk throughput is 180 MB/s for reads and 120 MB/s for writes. Generally speaking, larger VMs will achieve higher bandwidth.
For each IO pattern, the limits listed are for reads or writes. When discussing simultaneous reads and writes, the limits are on a sliding scale. The more reads being performed, the fewer writes can be performed and vice-versa.
Each of the following are example IOPS limits for simultaneous reads and writes:
| Read | Write |
|---|---|
| 3000 IOPS | 0 IOPS |
| 2250 IOPS | 3750 IOPS |
| 1500 IOPS | 7500 IOPS |
| 750 IOPS | 11250 IOPS |
| 0 IOPS | 15000 IOPS |
Each of the following are example throughput limits for simultaneous reads and writes:
| Read | Write |
|---|---|
| 180 MB/s | 0 IOPS |
| 135 MB/s | 30 MB/s |
| 90 MB/s | 60 MB/s |
| 45 MB/s | 90 MB/s |
| 0 MB/s | 120 MB/s |
SSD PD performance increases with the size of the volume. The IOPS performance increases faster for SSD PD than Standard PD. Throughput increases at the same rate.
The following table illustrates the performance limits for a 100 GB SSD Persistent Disk volume for each of the IO patterns.
| Expected IOPS / 100 GB | Expected throughput / 100 GB | Maximum Sustained throughput / VM | |
|---|---|---|---|
| Read | 3000 IOPS | 48 MB/s | 160 MB/s |
| Write | 3000 IOPS | 48 MB/s | 240 MB/s |
The VM limit for SSD Persistent Disk throughput is 160 MB/s for reads and 240 MB/s for writes. Generally speaking, larger VMs will achieve higher bandwidth.
SSD Persistent Disk volumes can be up to 1 TB. SSD Persistent Disk volumes reach the per-VM limit of 10000 random read IOPS at 333 GB. SSD Persistent Disk volumes reach the per-VM limit of 15000 random write IOPs at 500 GB.
While you have several inputs to consider in deciding the PD volume type and size that is right for your application, one factor you do not need to consider is the price of using your volume. Persistent Disk has no per-IO costs, so there is no need to estimate monthly I/O to calculate budget for what you will spend on disks.
Thus you only need to consider the relative costs of Standard PD versus SSD PD. Each is priced per GB. Standard PD is priced at $0.04 per GB and SSD PD is priced at $0.325 per GB. But since PD performance caps increase with the size of the volume, for IOPS oriented workloads it is instructive to look at the price per IOPS.
Standard PD is approximately $0.133 per random read IOPS and $0.0266 per random write IOPS. SSD PD is $0.011 per random read IOPS and $0.011 per random write IOPS.
Note that the price per IOPS for SSD PD is true up to the point where SSD PD reaches per-VM maximums. SSD PD reaches the per-VM limit of 10,000 random read IOPS at 333 GB and the per-VM limit of 15,000 random write IOPS at 500 GB. Standard PD reaches the per-VM limits at 10 TB.
Viewed in this light, we can give some quick rules of thumb for selecting the right Persistent Disk type.
The following table maps the most economical storage option based on the dominant requirement of your application:
| Dominant Requirement | Best Persistent Disk Choice |
|---|---|
| Storage | Standard PD |
| Throughput | Standard PD |
| IOPS | SSD PD |
Use the chart below as a quick reference for the performance and cost of some common Standard Persistent Disk volume sizes.
| Volume Size (GB) | Monthly Price | Sustained Random Read IOPS Limit | Sustained Random Write IOPS Limit | Sustained Read Throughput Limit (MB/s) | Sustained Write Throughput Limit (MB/s) |
|---|---|---|---|---|---|
| 10 | $0.40 | * | * | * | * |
| 50 | $2 | 15 | 75 | 6 | 4.5 |
| 100 | $4 | 30 | 150 | 12 | 9 |
| 200 | $8 | 60 | 300 | 24 | 18 |
| 500 | $20 | 150 | 750 | 60 | 45 |
| 1000 | $40 | 300 | 1500 | 120 | 90 |
| 2000 | $80 | 600 | 3000 | 180 | 120 |
| 5000 | $200 | 1500 | 7500 | 180 | 120 |
| 10000 | $400 | 3000 | 15000 | 180 | 120 |
* We suggest that you only use this volume size for boot volumes. IO bursting will be relied upon for any meaningful tasks.
Use the chart below as a quick reference for the performance and cost of some common SSD Persistent Disk volume sizes:
| Volume Size (GB) | Monthly Price | Sustained Random Read IOPS Limit | Sustained Random Write IOPS Limit | Sustained Read Throughput Limit (MB/s) | Sustained Write Throughput Limit (MB/s) |
|---|---|---|---|---|---|
| 10 | $3.25 | 300 | 300 | 4.8 | 4.8 |
| 50 | $16.25 | 1500 | 1500 | 24 | 24 |
| 100 | $32.50 | 3000 | 3000 | 48 | 48 |
| 200 | $65.00 | 6000 | 6000 | 96 | 96 |
| 333 | $108.225 | 10000 | 10000 | 160 | 160 |
| 500 | $162.50 | 10000 | 15000 | 160 | 240 |
| 1000 | $325.00 | 10000 | 15000 | 160 | 240 |
The following set of examples demonstrates how to select a Persistent Disk size based on performance requirements.
Suppose you have a database installation (small random IOs) that requires a maximum random write rate of 300 IOPs:
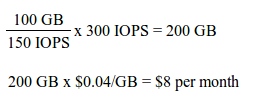

So if random write performance were your primary requirement, you would have the option to purchase a Standard Persistent Disk of at least 200 GB or an SSD Persistent Disk of at least 10 GB.
SSD Persistent Disk would be the less expensive choice.
Suppose you have a database installation (small random IOs) that requires a maximum sustained random read rate of 450 IOPs:


So if random read performance were your primary requirement, you would have the option to purchase a Standard Persistent Disk of at least 1500 GB or an SSD Persistent Disk of at least 15 GB.
SSD Persistent Disk would be the less expensive choice.
Suppose you have a data streaming service (large IOs) that requires a maximum sustained read throughput rate of 120 MB/s:

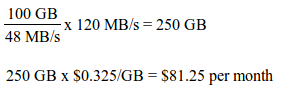
So if read throughput were your primary requirement, you would have the option to purchase a Standard Persistent Disk of at least 1000 GB or an SSD Persistent Disk of at least 250 GB.
Standard Persistent Disk would be the less expensive choice.
Suppose you have a database installation (small random IOs) that requires a maximum sustained random read rate of 450 IOPs and a maximum sustained random write rate of 300 IOPS. To satisfy the aggregate sustained performance requirements, create a volume with the performance requirements to satisfy both.
From examples 1 and 2 above:
200 GB + 1500 GB = 1700 GB
1700 GB x $0.04/GB = $68 per month
10 GB + 15 GB = 25 GB
25 GB x $0.325/GB = $8.13 per month
So if random read and write performance were your primary requirement, you would have the option to purchase a Standard Persistent Disk of at least 1700 GB or an SSD Persistent Disk of at least 25 GB.
SSD Persistent Disk would be the less expensive choice.
You may have never tested the IOPS or throughput you get from the hard drives used in your existing deployments, and so for the discussion of Persistent Disk performance you may need additional context. The following chart shows what size of volume is required to have the same top performance as a 7200 RPM SATA drive, which typically performs 75 IOPS or 120 MB/s.
| IO Pattern | Size of volume to approximate a typical 7200 RPM SATA drive |
|---|---|
| 75 small random reads | 250 GB |
| 75 small random writes | 50 GB |
| 120 MB/s streaming reads | 1000 GB |
| 120 MB/s streaming writes | 1333 GB |
Persistent Disks can give you the performance as described above, but the virtual machine must drive sufficient usage to reach the performance caps. So once you have sized your Persistent Disk volumes appropriately for your performance needs, your application and operating system may need some tuning.
In this section, we describe a few key elements that can be tuned for better performance and follow with discussion of how to apply some of them to specific types of workloads.
Persistent Disk supports DISCARD (or TRIM) commands, which allow operating systems to inform the disks when blocks are no longer in use. DISCARD support allows the operating system to mark disk blocks as no longer needed, without incurring the cost of zeroing out the blocks.
Enabling DISCARD can boost general runtime performance, and it can also speed up the performance of your disk when it is first mounted. Formatting an entire disk volume can be time consuming. As such, so-called "lazy formatting" is a common practice. The downside of lazy formatting is that the cost is often then paid the first time the volume is mounted. By disabling lazy initialization and enabling DISCARD commands, you can get fast format and mount.
Disabling lazy initialization and enabling DISCARD is handled by the Google-provided safe_format_and_mount utility discussed below.
If you do not use safe_format_and_mount you can:
-E lazy_itable_init=0,lazy_journal_init=0,discard
-o discard
Many applications have setting that influence their IO queue depth to tune performance. Higher queue depths increase IOPS, but can also increase latency. Lower queue depths decrease per-IO latency, but sometimes at the expense of IOPS.
To improve IO performance, operating systems, employ techniques such as readahead, whereby more of a file than was requested is read into memory with the assumption that subsequent reads are likely to need that data. Higher readahead increases throughput, but at the expense of memory and IOPs. Lower readahead increases IOPS, but at the expense of throughput.
|
On linux systems, you can get and set the readahead value with the blockdev command: $ sudo blockdev --getra /dev/<device> $ sudo blockdev --setra <value> /dev/<device> where the readahead value is <desired_readahead_bytes> / 512 bytes.
For example, if you desire a 8 MB readahead, 8 MB is 8388608 bytes (8 * 1024 * 1024). 8388608 bytes / 512 bytes = 16384 And you would set: $ sudo blockdev --setra 16384 /dev/<device> |
Reading and writing to Persistent Disk requires CPU cycles from your virtual machine. To achieve very high, consistent IOPS levels requires having CPUs free to process IO.
Databases, whether SQL or NoSQL, have usage patterns of random access to data. The following are suggested for IOPS-oriented workloads:
Streaming operations, such as a Hadoop job, benefit from fast sequential reads. As such, larger block sizes can increase streaming performance. The default block size on volumes is 4K. For throughput-oriented workloads, values of 256KB or above are recommended.
Boot volumes are typically small (10 GB by default). The bursting capability of Standard Persistent Disk small volumes will handle most package installation and boot-time IO requirements. If you have sustained IO to your boot volume (very aggressive logging, for example), you should make it bigger than 10 GB. In many cases the boot volume can handle logging requirements, but if logging is heavy, create a bigger boot volume, create a large logging volume, or write logs to a large data volume you already have.
Google provides a script called safe_format_and_mount (installed by default on Google images in /usr/share/google/), which can be called on a Compute Engine instance to format and mount a Persistent Disk volume. The "safe" notation indicates that if the volume has already been formatted, the script will not do so again.
safe_format_and_mount by default implements several of the optimizations noted above, including aligning filesystems on 4K boundaries when formatting, and setting the discard flag when mounting.
As the Persistent Disk product evolves, so will safe_format_and_mount. Calling safe_format_and_mount from your own scripts will allow you to pick up improvements as they are added.
It is all too easy for bugs in application or management software or user-error to lead to data loss. An effective backup strategy can mitigate the damage of such events. As discussed above, Persistent Disk volumes can be backed up quickly using snapshots. Take frequent snapshots and test your restore process regularly.
Persistent Disk removes many maintenance tasks typically associated with using block storage. Remember:
Persistent Disks provide a network block storage offering that is so high performing, consistent in implementation, and inexpensively priced that it allows local hard drives (and their limitations) to become a thing of the past on Google Compute Engine.
Use Google Compute Engine Persistent Disks for their:
Google will continually improve Persistent Disk features and performance to satisfy ever more demanding workloads and customer requirements.
For more information on Google Compute Engine Persistent Disks see:
[1] As of the date this paper was published. See the pricing page for the latest.