Planning for scale is essential to building an application today. There are now over 2 billion human internet users[1], and an ever-growing number of internet-connected devices.
Planning for scale means creating an infrastructure that will handle future demands; however, you don't want to pay for tomorrow's load until tomorrow. Therefore, planning for scale means creating a flexible infrastructure that can expand and contract with demand.
Fortunately, there are many open source and commercial software packages that have been built with scale in mind. MongoDB provides a NoSQL database engine built to handle the scale of modern applications.
Google Compute Engine is a great place to run MongoDB. The goal of this paper is to help you bring your MongoDB deployment to Google Compute Engine and take advantage of both the flexibility of Compute Engine's virtual environment, as well as the price-for-performance of Compute Engine Persistent Disks.
This paper is intended for anyone interested in deploying MongoDB on the Google Cloud Platform. After presenting fundamental MongoDB and Compute Engine deployment concepts, the paper will give important performance tips specific to running MongoDB on Google Compute Engine. It will then provide guidance for ongoing operations.
In this section, we will walk through key MongoDB architectural features and use example deployments to highlight the considerations for implementation on Google Compute Engine.
Key MongoDB architectural features are:
These architectural features have several software components:
Each of these components can have multiple software instances which (in a production environment) will be deployed on different machines. Google Compute Engine provides the deployment flexibility that allows you to run MongoDB in the configuration that is right for you.
MongoDB supports replication of data across multiple servers with the creation of replica sets. In a replica set:
Since replica sets must contain an odd number of voting members, the simplest non-trivial replica set would have three identically configured Compute Engine virtual machines. This replica set can:
A more complex replica set would have a heterogenous collection of server instances. Such a replica set can:
To support these additional uses, MongoDB allows one to configure members of a replica set differently, including:
priority 0, such that it never becomes the primary. Such a server may be used for reporting or to distribute read load.hidden from application servers, so only dedicated clients connect to it. Such a server may be used for reporting.MongoDB also allows you to save on resources. If you need only two copies of your data, you can create two MongoDB server instances and an arbiter member. An arbiter can vote but holds no replica set data. This gives you three voting members in the replica set, but without the full cost of a third server instance.
When adding members to a replica set to satisfy these different uses, Compute Engine allows you to choose different virtual machine types. This provides the flexibility to purchase the right amount of computing power for needs such as:
Compute Engine virtual machines can be deployed to multiple global regions, giving you choices of how to distribute your computing power. Each region is separated into multiple zones to enable mitigation against catastrophic failure of any single datacenter. Compute Engine zones are connected to each other and other Google services by Google's private global fiber network.
Figure 1 shows an example deployment that utilizes several of the features listed above.
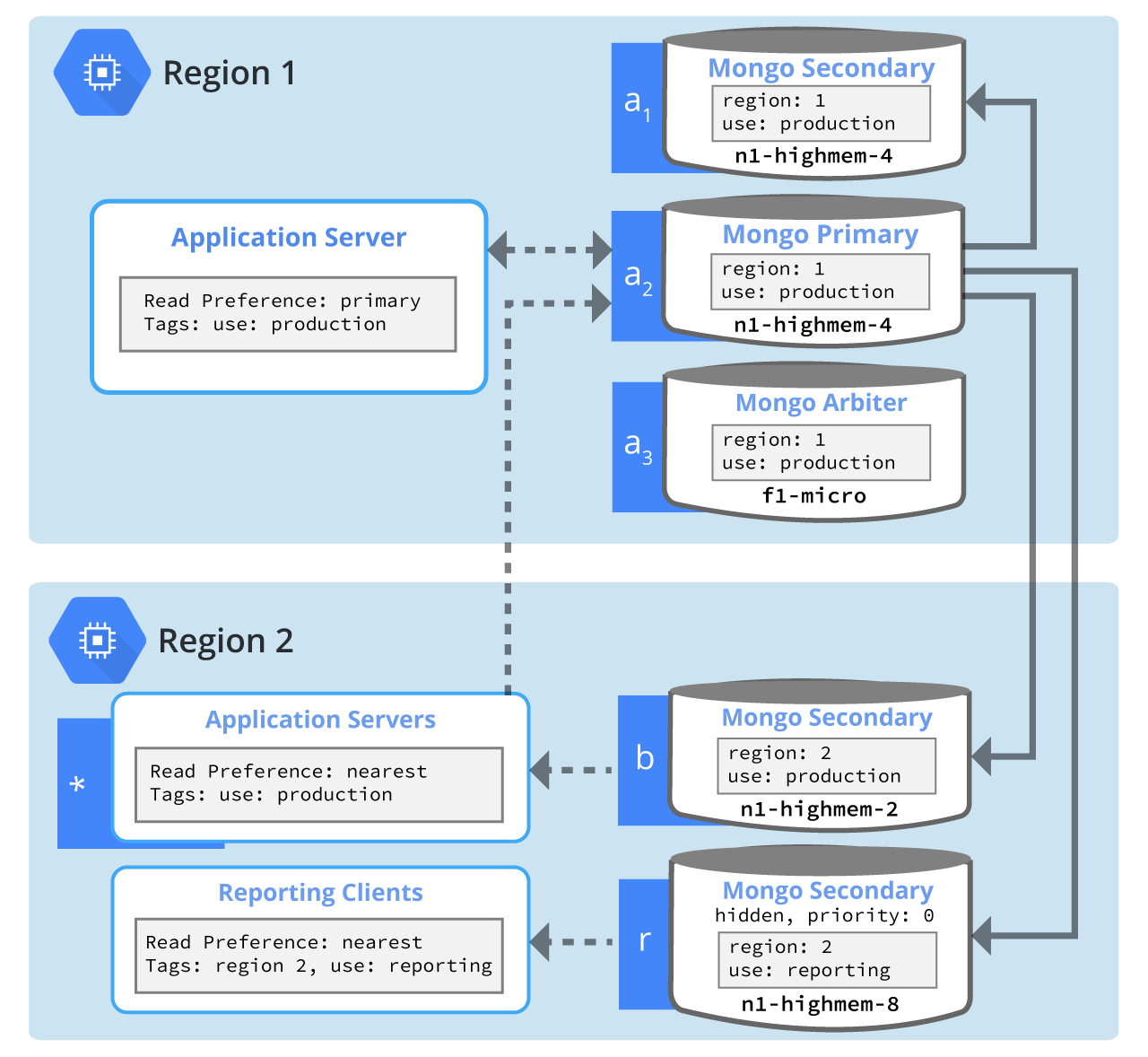
Figure 1: MongoDB replica set distributed across multiple Compute Engine regions for redundancy, read load distribution, regional responsiveness, and non-production workloads. Solid arrows designate flow of replicated data from the MongoDB primary to secondaries. Dotted arrows designate flow of data from application servers to the MongoDB primary (writes) and from MongoDB servers to clients (reads).
In Figure 1, Region 1 is the Compute Engine region where production servers reside. The majority of end-user traffic arrives at the Application Servers in this region. Barring a catastrophic outage, the MongoDB primary server should always be in this region.
In Figure 1, Region 2 is a Compute Engine region which is geographically close to a small but significant portion of the user base. In addition, Region 2 is geographically close to where the company's data analysts are located. MongoDB servers are configured with replica set tags such that clients can specify their desired servers by role and not by name. Clients additionally specify their Read Preference to either explicitly connect to a primary server or to the nearest server.
Compute Engine instances a1 and a2, each running a MongoDB server, are sized and configured identically, as either could be elected the primary. The read load from the production application servers always goes to the primary MongoDB server in the region.
Compute Engine instance a3 is configured to run a MongoDB arbiter. Arbiters are not required in a replica set, but in this example, an arbiter is deployed in the same zone as the other replica set members as a lower cost voting member. As this instance contains no replica set data and handles no end-user traffic, it is configured without a data disk and an f1-micro instance is used.
Compute Engine instance b is configured as a MongoDB secondary server for production traffic with a both a lower memory profile and fewer CPU cores than the MongoDB servers in Region 1. In this example, the assumption is that peak working set size and workload are lower than in Region 1.
Given its geographical distance from production application servers, instance b should never be elected primary as long as either a1 or a2 is healthy. Instance b should be configured with a low priority to make it unlikely, or (using priority 0) impossible, to be elected primary.
The Application Servers (*) in this region are configured to read from the nearest production secondary server. This provides better responsiveness for MongoDB queries, however, this approach should be undertaken with great caution. Since MongoDB writes always go to the primary server, the Application server software in this example must be coded appropriately to deal with reading stale data.
Compute Engine instance r is configured as a MongoDB secondary server for reporting workloads, with more memory than any of the production instances. By configuring the MongoDB server on this instance as hidden and with priority 0, only reporting applications will connect to this instance.
While MongoDB replication can be used for scaling a service by distributing reads across multiple secondary servers, doing so needs to be done with great care. Data on secondary servers is eventually consistent with the primary, so secondary servers can deliver stale results. Many applications can be coded to deal with stale data, but some cannot. At a minimum, handling stale results typically increases application complexity.
A preferred approach is to shard data across servers. By creating separate shards, MongoDB can provide a strictly consistent view of your data while distributing read and write load over multiple servers. You can then combine sharding with replication to achieve the other goals listed above.
Figure 2 shows an example combining sharding and replication.
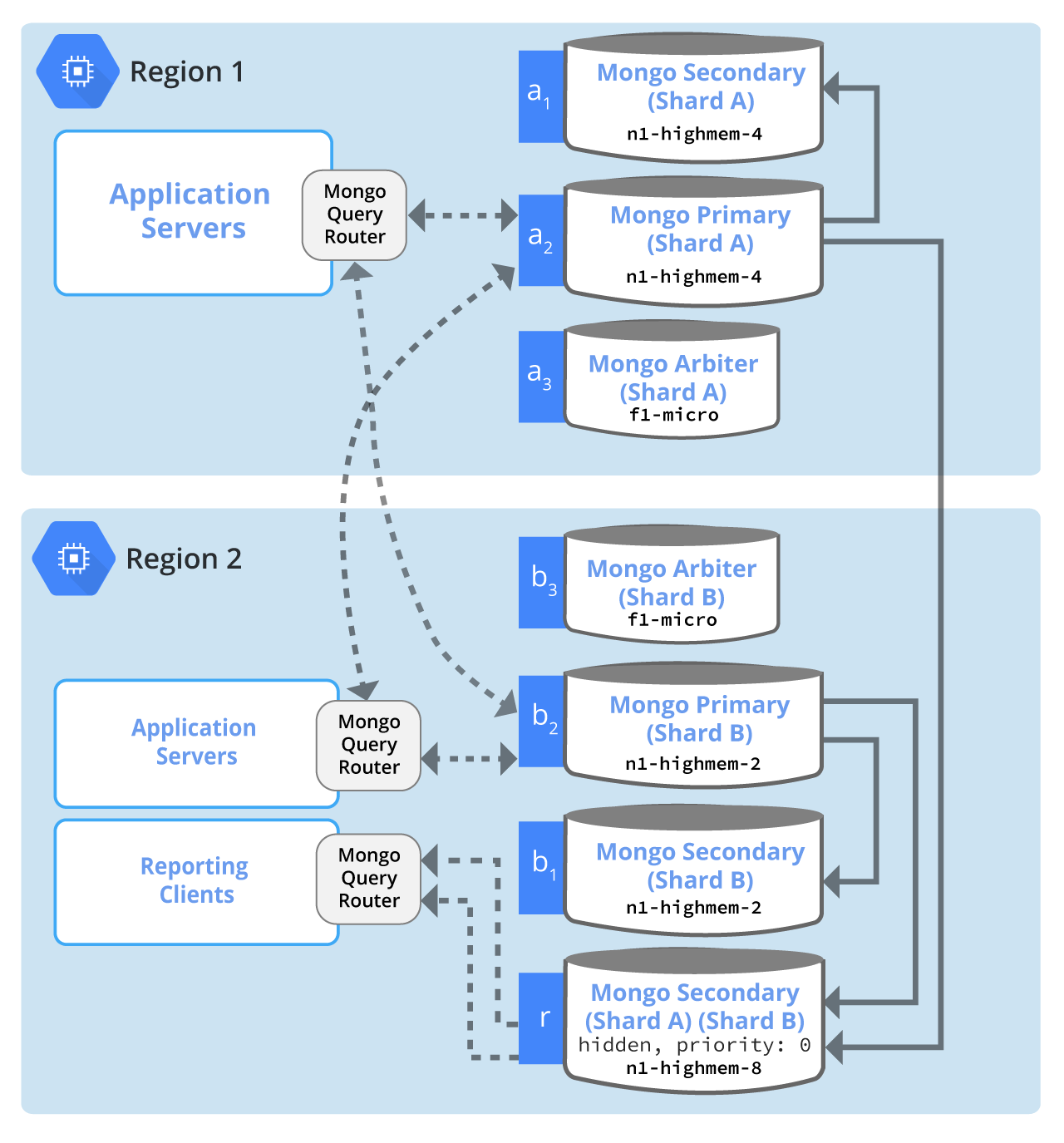
Figure 2: MongoDB distributed across multiple Compute Engine regions using sharding for redundancy, read load distribution, regional responsiveness, and non-production workloads. Solid arrows designate flow of replicated data from the MongoDB primaries to secondaries. Dotted arrows designate flow of data from application servers to the MongoDB primaries (writes) and from MongoDB servers to clients (reads).
Regions 1 and 2 in Figure 2 serve the same application objectives as in Figure 1:
Region 1 is the Compute Engine region where production servers reside. The majority of end-user traffic arrives at the Application Servers in this region.
Region 2 is a Compute Engine region which is geographically close to a small but significant portion of the user base. In addition, Region 2 is geographically close to where the company's data analysts are located.
In this example, there is an assumption that the data most frequently accessed by the users in Region 1 is different than the users in Region 2. By creating two shards and using tag aware sharding, the data that is most frequently accessed by users in Region 1 is stored in Region 1, and the data most frequently accessed by users in Region 2 is stored in Region 2.
For clients, the MongoDB Query Router transparently routes queries to the appropriate primary server(s). In the above example no production application ever reads from a secondary server. Thus the production application never needs handle the complexity of stale reads and eventual consistency.
Compute Engine instances a1 and a2, each running a MongoDB server, are sized and configured identically, as either could be elected the primary for Shard A. The read load from the production application servers always goes to the primary MongoDB servers. The bulk of the client-server traffic is expected to stay within the region.
Compute Engine instance a3 is configured to run a MongoDB arbiter server. Arbiters are not required in a replica set, but in this example, an arbiter is deployed in the same zone as the other replica set members as a lower cost voting member. As this instance contains no replica set data and handles no end-user traffic, it is configured without a data disk and an f1-micro instance is used.
Compute Engine instances b1 and b2, each running a MongoDB server, are sized and configured identically, as either could be elected the primary for Shard B. The read load from the production application servers always goes to the primary MongoDB servers. The bulk of the client-server traffic is expected to stay within the region.
Compute Engine instance b3 is configured to run a MongoDB arbiter server. As this instance contains no replica set data and handles no end-user traffic, it is configured without a data disk and an f1-micro instance is used.
Compute Engine instance r is configured as a MongoDB secondary server for both Shard A and Shard B for reporting workloads, with more memory than any of the production instances. By configuring the MongoDB server on this instance as hidden and with priority 0, only reporting applications will connect to this instance.
Instance r is also configured as a non-voting member of the Shard A and Shard B replica sets. A valid alternative here would be to remove the arbiter instances a3 and b3 and allow instance r to be a voting member. However doing so could impact primary instance election for the replica set members for Shard A. If communications were lost between regions 1 and 2, primary election could not proceed.
Performance tuning of MongoDB on Google Compute Engine starts with performance tuning of your MongoDB software. No amount of well-configured hardware can make up for an inefficient database design and insufficient or ineffective indexing. Refer to Optimization Strategies for MongoDB.
Once the MongoDB architecture and query patterns have been decided, there are some important considerations for deployment of MongoDB on Google Compute Engine.
As with any performance tuning, all suggestions below are guidelines that should be validated for your MongoDB workloads.
Google Compute Engine provides many virtual machine types, giving you options for selecting the right number of CPU cores and the right amount of memory for your virtual machines.
MongoDB servers perform best when disk access can be minimized. The recommended way to do this is to size MongoDB server instances such that the active working data set can be kept in memory. Different applications will have different demands, but more memory will often be a more cost-effective way to improve performance than more cores.
If your deployment includes MongoDB arbiter servers, consider using f1-micro instances. Arbiter instances are mostly idle, exchanging heartbeat information with MongoDB servers and only becoming significantly active for a short period when a new primary needs to be elected. Using a shared-core instance such as f1-micro or g1-small is an inexpensive way to reserve critical CPU cycles which are needed infrequently.
Persistent disks offer high performing and consistent block storage for Compute Engine instances. Disk performance scales with the size of the disk up to the maximum capacity of its associated virtual machine.
Thus when sizing disks for your MongoDB data:
Note that if the disk performance limits of your virtual machine type are not sufficient for your needs, then you will need to shard your data.
It is a common recommendation to separate components onto different storage devices. Persistent disks already stripes data across a very large number of volumes. There is no need to do it yourself.
MongoDB journal data is small and putting it on its own disk means either creating a small disk with insufficient performance or creating a large disk that goes mostly unused. Put your MongoDB journal files on the same disk as your data. Putting your MongoDB journal files on a small persistent disk will dramatically decrease performance of database writes.
There are a few system settings that can impact the runtime performance of MongoDB. Additional details on these settings can be found at http://docs.mongodb.org/ecosystem/platforms/google-compute-engine/.
Open disk files and open network connections are tracked by the host operating system and are collectively treated as open files. This requires that system resources and operating systems put configurable limits on them.
The default limits are typically in the low thousands, while a server running MongoDB often needs to maintain tens of thousands of open files.
Additional details can be found at http://docs.mongodb.org/manual/reference/ulimit/.
Operating systems have a heartbeat mechanism such that either end of a network connection knows that the other is still connected. How long one end can go without hearing from the other is called the "keepalive". When one end of the connection has not heard from the other for a sufficient period of time, the connection will be considered dead and cleaned up.
A MongoDB server with a high inbound connection rate can run into a problem where the network stack has kept dead connections around too long. To prevent this, it is recommend that you lower the TCP keepalive time from its default.
Additional details can be found at http://docs.mongodb.org/manual/faq/diagnostics/.
When an application requests that part of a file be read from disk, the operating system will typically read more than the requested amount and cache it, with the assumption that the application will soon request more of the file. This mechanism is called "readahead".
MongoDB access to data on disk is typically random, rather than sequential. Thus large readahead does not help and will typically hinder performance as memory, CPU, and network resource are wasted doing unnecessary readahead.
It is recommended that you lower readahead values on your MongoDB data volume. Additional details can be found at http://docs.mongodb.org/manual/administration/production-notes/.
MongoDB is able to shard data while continuing to service requests and will prioritize processing end-user traffic over processing sharding requests. This means that you do not need to take your database down in order to shard.
However sharding does use network, memory, and CPU resources. From the MongoDB Sharding Guide:
Important: It takes time and resources to deploy sharding. If your system has already reached or exceeded its capacity, it will be difficult to deploy sharding without impacting your application.
As a result, if you think you will need to partition your database in the future, do not wait until your system is over capacity to enable sharding.
As your system grows, you end up with more data needing to be sharded using fewer resources. Depending on the size of your database and the available compute resources for your cluster, sharding can take hours or days.
With Google Compute Engine, you can add new virtual machines as you need them, and you have many choices in the amount of CPU and memory for your deployments. By monitoring your MongoDB infrastructure and configuring smaller shards over larger ones, you can keep your deployments nimble and stay on top of your resource needs.
Compute Engine persistent disks live independently from the instances to which they are attached. Thus you can delete a virtual machine instance at any time, choose not to delete the associated persistent disks, and later start a new instance with the same disks. In this process, the virtual machine type of the new instance need not be the same as the original instance. This can allow you to upgrade and downgrade your hardware quickly and easily.
The ability to quickly change virtual machine type along with MongoDB replication, allows one to easily change virtual machine type for an entire replica set with minimal impact to production traffic. Consider the following sequence of operations:
For each secondary server:
When replication to secondary instances has caught up, then for the primary server:
At the time the primary server is deleted, primary election will occur within the replica set and one of the secondaries whose hardware has already been upgraded or downgraded will be elected primary. After the original primary is started, it will join the replica set as a secondary.
Quick tip on server restarts
When a MongoDB server restarts, data will not initially be in memory and will be loaded into memory on-demand. This can significantly impact performance and so MongoDB recommends explicitly bringing data from storage into memory using the touch command.
When following the above steps to upgrade or downgrade your VMs, use the touch command to improve secondary warm-up and speed the time to complete your maintenance.
As discussed above in the section "Shard early" above, it is a common pitfall to wait too long to shard, creating a real problem for a production cluster. Should you find yourself in this situation, there may be a way to complete the needed sharding without impacting production traffic.
If your MongoDB servers are a not already running at the largest available Compute Engine instances, then consider the following sequence of operations:
n1-standard-4 to n1-standard-8. If your instances are memory bound, move from n1-standard-4 to n1-highmem-4.Assuming step 1 alleviates your immediate resource crunch, you should have the capacity to shard with limited impact to production traffic.
MongoDB provides great architectural flexibility to build out a highly scalable, highly available, data-driven application. Google Compute Engine provides a computing platform that allows you to take advantage of it.
With a large number of machine types to select from, high performing persistent disks, and a high speed global fiber network, you can build out the MongoDB deployment to fit your needs.
For more information on Google Compute Engine and MongoDB see:
[1] According to http://www.internetworldstats.com/stats.htm (3/1/2014)